Das Projekt floatet quasi über alle Core und zieht sich das Quenten am Power, wo er es dann aktuell findet.
In der Variante mit der app. Zuordnung werden die Core zugewiesen - da braucht das Projekt nichts zu suchen, wo er Rechenzeit findet.
Entscheidend ist für mich, dass ich so dauerhaft 100% gewiss (Controllfreak) Zugriff an die dann als frei definierten Core habe;
z.B. für Musik und Filme, Bildbearbeitung, Surfen und Email usw.
Es wäre ein Experiment wert, zu gucken, ob die Core-Limitierung (hier: 25%) durch das "freie floaten" aufgehoben wird über alle Cores hinweg.
Edit: Gefunden im SG-Forum ([ETA]MrSpadge am 30.6.2015)
Offenbar hat AMD bei Poem auch einen OCL-Vorteil, weil der Zugriff auf die CPU rund 10 % beträgt - und damit quasi "Core-los" (wie GPUGRID).Inzwischen hab ich bei POEM im Forum gelesen, dass die aktuelle App für AMD GCN Chips (also alles ab der 7000'er Serie) optimiert ist und dort ca. 50% Effizienz erreicht. Also 50% der theoretischen Leistung können auch praktisch genutzt werden, was ein exzellenter Wert ist. Maxwell tun diese Optimierungen auch sehr gut, trotzdem liegen diese Chips bei nur ca. 30%. Alles ältere (Kepler, Fermi, AMD VLIW) ist weit abgeschlagen. Aber zumindest wohl nicht schlechter als vor der Optimierung.
@Marcel: die app_config.xml kann man in jedem Projekt benutzen, Das ist ein Mechanismus, den BOINC selbst mitbringt. Verschiedene Projekte zugleich auf einer GPU laufen zu lassen kann man schief gehen, funktioniert aber häufig.
Ansonsten fehlt dir (soweit ich dich richtig verstehe) noch dieser Baustein: mit diiesen Angaben von "x CPU" und "y GPU" beeinflusst du in keinster Weise die App direkt. Die merkt davon gar nichts. Was du änderst ist, wie viele Ressourcen (CPUs & GPUs) BOINC für diese Aufgaben einplant und wie viele es davon startet, um die Ressourcen auszulasten.
Bei den GPUs ist das recht klar: BOINC startet so viele Aufgaben, dass die Summie der "y GPUs", die im BOINC Manager angezeigt wird, die Summe der physikalisch vorhandenen GPUs nicht übersteigt. Diese Aufgaben teilen sich die GPUs dann sehr einfach: jeder ist abwechselnd dran und kann die GPU so lange haben, wie er mag.
Bei den CPUs ist es ähnlich, mit (mindestens) 2 Unterschieden:
- das BS kann seinen Scheduler einsetzen, was deutlich besseres Multitasking mit Prioritäten etc. erlaubt
- bei z CPU-Kernen iim Rechner startet BOINC Aufgaben, so dass die Summe der zugehörigen CPU-Werte z+1 nicht übersteigt
D.h. bei 4 Kernen und 1 GPU würden bei "0.5 CPU, 0.5 GPU" für POEM insgesamt 1 CPU-Kern reserviert werden, um auf genau 1 GPU zu kommen. Damit bleiben 3 Kerne für andere Aufgaben. Da POEM@AMD nur ca. 10% eines Kerns nimmt, bleiben also 80% eines Kerns von BOINC unangetastet. Würdest du jedoch "0.3 CPUs, 0.3 GPUs" einstellen, würden 3 POEM GPU-Tasks laufen (um unter 1 GPU zu bleiben). Dazu würde BOINC jedoch 4 CPU-Tasks starten, 4+3*0.3 = 4.9 < 5.
MrS
Das spricht auf jeden Fall für eine AMD-Karte...und ich werde mal meine Meinung dazu nochmal überdenken.
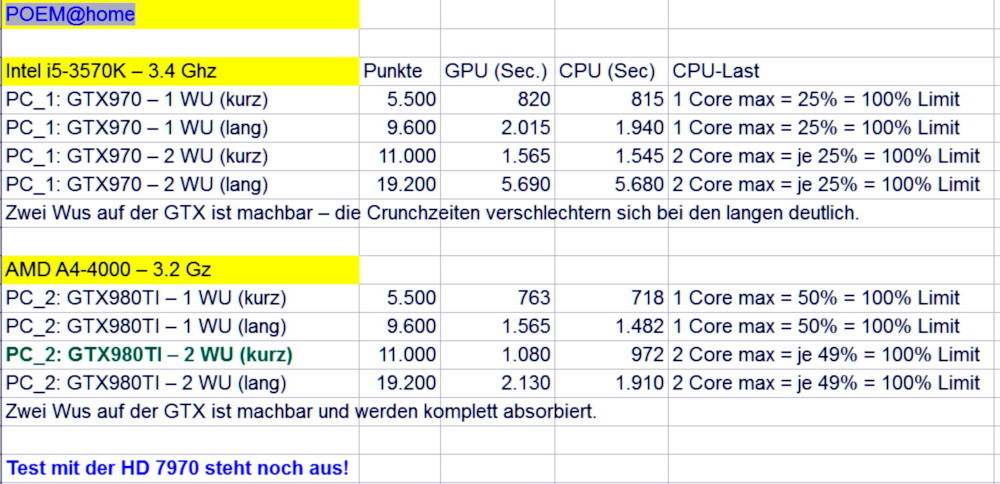
Edit 2: Lösch ich die app_config.xml bzw. setze den CPU-Wert ebenfalls auf 0,1 - dann arbeitet das System trotzdem mit 25% Core = 100% Limit.
Vielleicht kann jemand einen Vergleich machen?
Edit 3: Bei GPUGRID ist es so, dass bei meinem i5 ohne die app_config.xml die CPU-Auslastung wie gewohnt bei 0,1 ~ 0,2 % liegt; jedoch bei meinem AMD A4-4000@3.2 Ghz steigt die CPU-Auslastung auf 25%-30% (bei Duo-Core).
Also floating hin und her, ein Core zieht sich den WU und füttert ihn.
[auch beim Limit ruckelt und zuckelt nichts (nur die maximale mögliche Fütterung leidet) - solange das System insgesamt Reserven hat.
Den Task-Manager befragen).
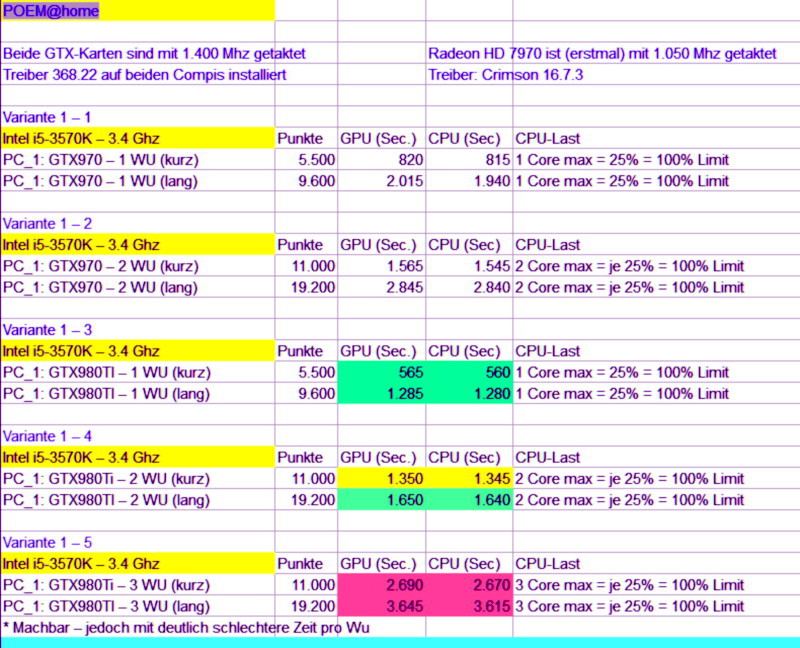
Edit 4: Ich bin jetzt stolzer baldiger Besitzer einer HIS Radeon HD 7970!
Hoffe sehr, dass die Graka mich auch erreicht und ich die entsprechend prüfen kann.
Dann werde ich sehen, was bei Poem rum kommt.
Edit 5: Auch ohne app_config.xml ist die Auslastung bei 25% Core = 100% Limit.
Dazu noch eine Betrachtung:
Der Compi hat viele Aufgaben zu erledigen; teilweise PC-generierte Dienste im Hintergrund oder bestimmte vom User gestartete Programme / Anwendung.
Das können dann schon mal 30 - 50 - 100 task sein, die da alle auf die Computer-Rechenzeit zugreifen.
Bei mir also auf den 4-Core-CPU.
Wenn man den Dingen ihren Lauf läßt, dann organisiert das BS die jeweiligen Zugriffe entsprechend der Priorisierung, die die jeweiligen Anwendungen zugeordnet bekommen.
Ist wenig wenig Trubel im Compi dann sind alle Programme ganz relaxe.
Problematisch wird es dann, wenn etliche leistungsstarke Anwendung ihren Zugriff geltend machen.
Dann erfolgt die Rangfolge nach der Priorisierung.
Poem hat z.B. die Priorisierung "niedriger als normal".
Wenn mensch also unvernünftig ist und Videobearbeitung macht bei gleichzeitigen Crunchen und noch irgednwas leistungsfressenden, dann "knallt" es;
entweder kommt es zum einfrieren und Absturz bzw. oder die Bearbeitung wird zäh und langsam, weil die Computerzeit für jeden task nur noch verkürzt zur Verfügung steht.
Die maximale Auslastung eines task wäre dann maximal ein core.
Indem Moment wo ich eine app_config.xml anlege definiere ich bereits eine Zuordnung auf 0,5 oder 1,0 CPU wie auch immer
und habe damit vorsorglich mit dieser Einstellung eine manuelle Priorisierung vorgenommen.
Alle anderen laufenden task müssen sich jetzt noch um die verbliebenen 3 Core balgen,
während Poem priviligiert 1 Core für sich hat.
Wie gesagt: das muss man nicht machen, wenn sowieso alle task in ausreichender zeit sich die Compi-zeit (in ms) teilen.
Nur wenn es bei
Hinzu kommt natürlich sowieso, wenn man mehrere WUs auf eine Graka laufen lassen will; womöglich noch von unterschiedlichen Projekten -
das regelt sich nicht von alleine.
Soweit mein Verständnis - ich lese mir gerne andere Ansichten dazu durch.
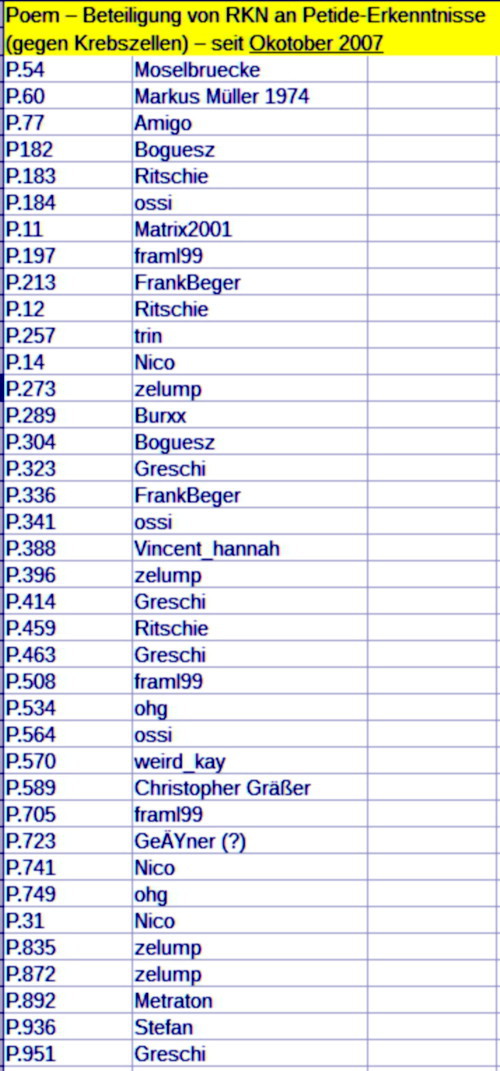
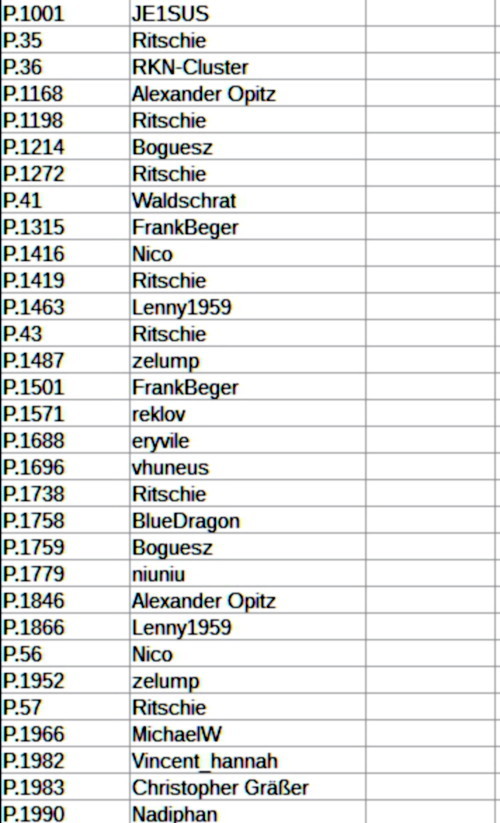
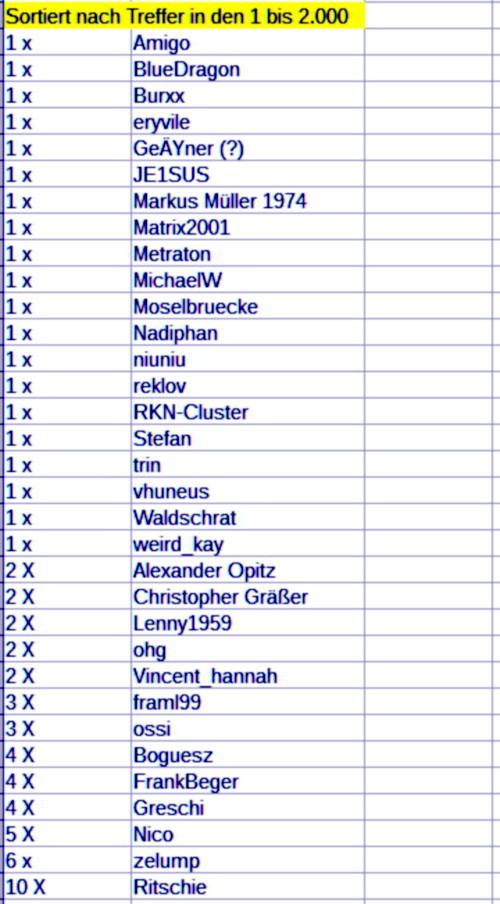


 s
s